在軟件系統(tǒng)類的創(chuàng)新創(chuàng)業(yè)競賽、新苗人才計劃、國家級大學(xué)生創(chuàng)新創(chuàng)業(yè)訓(xùn)練計劃(國創(chuàng)/大創(chuàng))等項目中,一份邏輯清晰、技術(shù)詳實、前瞻可行的《技術(shù)方案》是項目計劃書或申報書的核心骨架與靈魂。它不僅是評審專家評估項目技術(shù)含量、創(chuàng)新性與可行性的關(guān)鍵依據(jù),更是團隊自身厘清技術(shù)路線、規(guī)避開發(fā)風(fēng)險、規(guī)劃資源投入的行動藍(lán)圖。本文旨在提供一個約五千字的系統(tǒng)性與建議,聚焦于如何撰寫技術(shù)方案中至關(guān)重要的“數(shù)據(jù)處理與存儲支持服務(wù)”部分,助力項目脫穎而出。
一、 技術(shù)方案的整體定位與結(jié)構(gòu)框架
在動筆之前,須明確技術(shù)方案在整體文檔中的角色:它是對“做什么”和“怎么做”的技術(shù)性深度闡釋,需與項目概述、市場分析、商業(yè)模式等部分緊密呼應(yīng),共同證明項目的價值與可實現(xiàn)性。
一個完整的技術(shù)方案通常包含以下模塊:
- 系統(tǒng)架構(gòu)設(shè)計:包括總體架構(gòu)圖(如分層架構(gòu)、微服務(wù)架構(gòu))、技術(shù)選型說明。
- 核心功能模塊詳述:分解系統(tǒng)功能,說明各模塊的技術(shù)實現(xiàn)思路。
- 數(shù)據(jù)處理與存儲方案(本文核心):詳細(xì)闡述數(shù)據(jù)從產(chǎn)生到消亡的全生命周期管理策略。
- 關(guān)鍵技術(shù)與創(chuàng)新點:突出項目的技術(shù)壁壘與獨創(chuàng)性。
- 系統(tǒng)性能、安全與可靠性設(shè)計:定義非功能性指標(biāo)及保障措施。
- 開發(fā)計劃與技術(shù)風(fēng)險:劃分開發(fā)階段、預(yù)估技術(shù)難點與應(yīng)對策略。
二、 數(shù)據(jù)處理與存儲支持服務(wù)方案詳解
這是技術(shù)方案中最能體現(xiàn)項目技術(shù)深度和嚴(yán)謹(jǐn)性的部分。對于數(shù)據(jù)驅(qū)動的軟件系統(tǒng)(如大數(shù)據(jù)分析平臺、物聯(lián)網(wǎng)應(yīng)用、社交網(wǎng)絡(luò)、電商系統(tǒng)等)尤為重要。撰寫時應(yīng)遵循“數(shù)據(jù)流”與“生命周期”兩條主線。
第一部分:數(shù)據(jù)處理流程設(shè)計
- 數(shù)據(jù)源分析:
- 類型:明確數(shù)據(jù)來源(如用戶操作日志、傳感器實時流、第三方API、數(shù)據(jù)庫快照、上傳的文件等)。
- 格式與頻率:描述數(shù)據(jù)格式(JSON、CSV、二進(jìn)制流等)、數(shù)據(jù)生成頻率(持續(xù)流、定時批量)、數(shù)據(jù)量級預(yù)估(日增/月增數(shù)據(jù)量)。
- 示例(競賽項目中):“本項目移動端App每日產(chǎn)生約10萬條用戶行為事件日志(JSON格式),同時每小時從公開氣象API接口獲取一次城市天氣數(shù)據(jù)。”
- 數(shù)據(jù)采集與接入:
- 技術(shù)選型與理由:根據(jù)數(shù)據(jù)源特性選擇工具。如實時流采用Apache Kafka、Flink;日志采集用Logstash、Filebeat;批量導(dǎo)入用Sqoop、DataX。對于輕量級競賽項目,可選用云服務(wù)商提供的托管服務(wù)(如AWS Kinesis、阿里云DataHub)或開源中間件,并說明選型理由(如社區(qū)活躍、與后續(xù)組件兼容、學(xué)習(xí)成本低)。
- 數(shù)據(jù)緩沖:說明如何應(yīng)對數(shù)據(jù)洪峰,保障系統(tǒng)穩(wěn)定性。
- 數(shù)據(jù)預(yù)處理與清洗:
- 清洗規(guī)則:定義如何處理缺失值、異常值、重復(fù)數(shù)據(jù)、格式不一致等問題。
- 轉(zhuǎn)換與標(biāo)準(zhǔn)化:說明數(shù)據(jù)歸一化、編碼轉(zhuǎn)換(如one-hot編碼)、時間戳標(biāo)準(zhǔn)化等步驟。
- 實現(xiàn)方式:可采用ETL工具(如Apache NiFi)、編寫Spark/Python清洗腳本,或在流處理框架中定義清洗算子。
- 數(shù)據(jù)計算與分析:
- 批處理與流處理:根據(jù)業(yè)務(wù)需求劃分。批處理用于T+1報表、歷史數(shù)據(jù)挖掘;流處理用于實時監(jiān)控、實時推薦。
- 計算框架:批處理可選Spark、Hive;流處理可選Flink、Spark Streaming;實時查詢可選ClickHouse、Druid。結(jié)合項目規(guī)模和團隊技術(shù)棧,選擇最合適的框架。
- 算法模型集成:如果涉及機器學(xué)習(xí),需說明訓(xùn)練數(shù)據(jù)如何準(zhǔn)備、模型如何上線服務(wù)(在線預(yù)測API)。
第二部分:數(shù)據(jù)存儲架構(gòu)設(shè)計
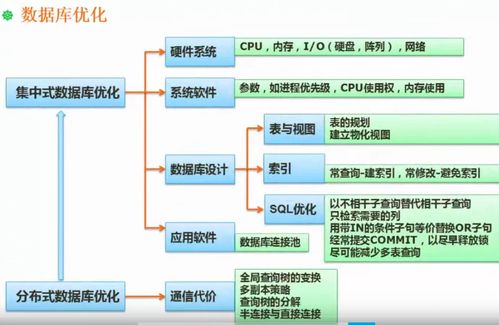
- 存儲選型策略(核心):根據(jù)數(shù)據(jù)的使用場景(在線事務(wù)、離線分析、緩存、搜索)選擇合適的存儲系統(tǒng),遵循“Right Tool for the Right Job”原則。
- 結(jié)構(gòu)化數(shù)據(jù)(關(guān)系型數(shù)據(jù)庫):如MySQL、PostgreSQL。用于存儲用戶賬戶、訂單交易等需要強一致性、事務(wù)支持的核心業(yè)務(wù)數(shù)據(jù)。需說明表結(jié)構(gòu)設(shè)計要點(范式考量、索引策略)。
- 非結(jié)構(gòu)化/半結(jié)構(gòu)化數(shù)據(jù)(NoSQL):
- 文檔型(如MongoDB):存儲JSON格式的用戶畫像、商品詳情。
- 鍵值型(如Redis):用作高速緩存(會話緩存、熱點數(shù)據(jù))、排行榜。
- 列式存儲(如HBase、Cassandra):適用于海量數(shù)據(jù)、高并發(fā)隨機讀寫的場景(如用戶行為日志查詢)。
- 時序數(shù)據(jù)庫(如InfluxDB、TDengine):專為帶時間戳的監(jiān)控指標(biāo)、傳感器數(shù)據(jù)設(shè)計,高效壓縮,查詢快。
- 數(shù)據(jù)倉庫:如Apache Hive、StarRocks、Snowflake(云上)。用于整合多源數(shù)據(jù),支持復(fù)雜的OLAP分析。需簡要描述維度建模思想(星型/雪花模型)。
- 對象存儲:如AWS S3、阿里云OSS、MinIO(自建)。用于存儲圖片、視頻、文檔等靜態(tài)大文件,成本低、擴展性強。
- 數(shù)據(jù)分層設(shè)計(數(shù)據(jù)湖/倉庫架構(gòu)):
- 提出將原始數(shù)據(jù)、清洗后數(shù)據(jù)、輕度匯總數(shù)據(jù)、高度聚合/應(yīng)用數(shù)據(jù)分層存儲的理念(如ODS->DWD->DWS->ADS)。這體現(xiàn)了對數(shù)據(jù)治理的深入思考,極具專業(yè)性。
- 說明各層的數(shù)據(jù)格式、存儲介質(zhì)(HDFS、對象存儲)、保留策略及訪問權(quán)限。
- 數(shù)據(jù)備份、容災(zāi)與歸檔方案:
- 備份策略:定期全量備份+增量備份的頻率與方式。
- 容災(zāi):考慮同城異地備份,或利用云數(shù)據(jù)庫的多可用區(qū)部署。
- 冷熱數(shù)據(jù)分離:定義將不常訪問的歷史數(shù)據(jù)遷移至更低成本存儲(如從HDFS至對象存儲)的策略。
第三部分:數(shù)據(jù)服務(wù)與API設(shè)計
數(shù)據(jù)處理和存儲的最終目的是提供服務(wù)。需規(guī)劃如何將數(shù)據(jù)能力暴露給前端或其他系統(tǒng)。
- 數(shù)據(jù)服務(wù)層:設(shè)計統(tǒng)一的RESTful API或GraphQL接口,對外提供數(shù)據(jù)查詢、寫入服務(wù)。
- 數(shù)據(jù)可視化支持:說明如何為管理后臺或報表系統(tǒng)提供數(shù)據(jù)接口,可提及集成開源BI工具(如Superset、Metabase)或自研圖表組件。
- 實時數(shù)據(jù)推送:如需實時儀表盤或通知,說明使用WebSocket或Server-Sent Events (SSE)技術(shù)。
三、 撰寫要點與提升技巧
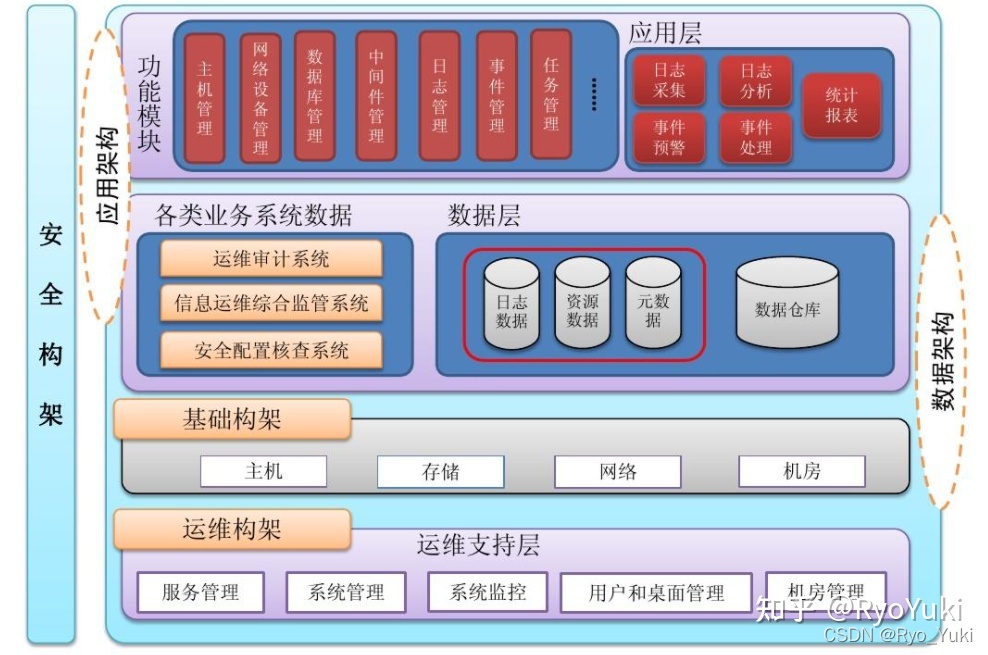
- 圖文并茂,架構(gòu)圖至關(guān)重要:繪制清晰的數(shù)據(jù)流向圖(Data Flow Diagram)和數(shù)據(jù)存儲分層架構(gòu)圖。使用標(biāo)準(zhǔn)的圖形符號(如UML),讓專家一目了然。
- 緊扣“創(chuàng)新”與“可行性”:技術(shù)選型不必盲目追求最新最炫,但要合理。對于學(xué)生項目,優(yōu)先選擇主流、有豐富學(xué)習(xí)資源、社區(qū)支持好的技術(shù)。在某個環(huán)節(jié)(如使用一種新型時序數(shù)據(jù)庫優(yōu)化查詢效率,或設(shè)計一種獨特的流處理算法)體現(xiàn)創(chuàng)新性思考。
- 量化指標(biāo):盡可能給出量化預(yù)估,如“預(yù)計系統(tǒng)上線初期存儲容量需求為500GB,隨著用戶增長,年數(shù)據(jù)增量約2TB”,“要求核心API接口響應(yīng)時間P95 < 200ms”。
- 考慮競賽/申報特點:
- 完整性:即使項目初期不實現(xiàn)所有高級特性(如復(fù)雜的容災(zāi)),也應(yīng)在方案中體現(xiàn)未來演進(jìn)的可能。
- 成本意識:提及將利用云服務(wù)的免費額度、校園優(yōu)惠,或使用開源軟件降低成本和運維難度。
- 團隊能力匹配:說明團隊成員已具備或計劃學(xué)習(xí)相關(guān)技術(shù),證明方案的執(zhí)行有保障。
- 關(guān)聯(lián)業(yè)務(wù)場景:始終將技術(shù)方案與項目要解決的實際業(yè)務(wù)問題掛鉤。例如,“為解決用戶行為分析的實時性需求,我們引入了Flink流處理框架,使得推薦模型能基于最近10分鐘的用戶點擊行為進(jìn)行實時更新。”
四、 常見誤區(qū)與規(guī)避
- 誤區(qū)一:堆砌技術(shù)名詞,邏輯混亂。→ 規(guī)避:以數(shù)據(jù)流為主線,講好“數(shù)據(jù)故事”。
- 誤區(qū)二:存儲方案單一,一把梭用MySQL。→ 規(guī)避:深入分析數(shù)據(jù)多樣性,采用混合持久化策略。
- 誤區(qū)三:忽視數(shù)據(jù)安全與隱私。→ 規(guī)避:增加章節(jié)說明數(shù)據(jù)脫敏、加密傳輸存儲、訪問權(quán)限控制(RBAC)的設(shè)計。
- 誤區(qū)四:方案脫離實際,無法落地。→ 規(guī)避:進(jìn)行技術(shù)預(yù)研,評估學(xué)習(xí)成本和開發(fā)周期,制定分階段實施計劃。
###
撰寫一份出色的數(shù)據(jù)處理與存儲技術(shù)方案,需要將系統(tǒng)的業(yè)務(wù)需求翻譯成精準(zhǔn)的技術(shù)語言,并在先進(jìn)性與可行性、完整性與聚焦性之間取得平衡。它不僅是通向競賽獎項或項目資助的敲門磚,更是團隊在項目開發(fā)前進(jìn)行的一次至關(guān)重要的“沙盤推演”。投入時間精心打磨此部分內(nèi)容,必將為整個項目的成功奠定堅實的技術(shù)基石。希望本指南能為您的軟件系統(tǒng)創(chuàng)新創(chuàng)業(yè)之旅提供清晰的指引。